
Getting Started with AI in .NET: A Simple Guide to Microsoft.Extensions.AI
In the ever-evolving landscape of software development, integrating AI capabilities into .NET applications has become a game-changer. As a developer with a passion for exploring new technologies, I’ve delved into the world of Large Language Models (LLMs) and discovered how Microsoft.Extensions.AI can streamline this process.
Large Language Models (LLMs) are transforming how developers build intelligent applications. From automating tasks like text summarization to creating dynamic conversational bots, the possibilities are endless. While many developers have explored APIs like OpenAI’s GPT models, there is now a growing opportunity to run LLMs directly on your machine, making them more accessible and private. One tool that makes this feasible is Ollama.
In this article, we’ll explore the role of LLMs in modern software development, dive into how the Microsoft.Extensions.AI library simplifies their integration into .NET applications, and learn how to leverage Ollama for running these models locally.
What Are Large Language Models (LLMs)?
Large Language Models (LLMs) are advanced AI systems designed to process and generate human-like text. They excel at understanding context and linguistic patterns, enabling them to perform tasks such as:
- Completing or summarizing pieces of text
- Classifying or analyzing sentiments in language
- Engaging in conversational interactions that feel natural
Their ability to mimic human understanding has made LLMs a cornerstone of AI-powered applications. Traditionally, these models were only accessible via cloud APIs provided by platforms like OpenAI or Azure, but local deployment solutions have recently emerged as viable alternatives.
What Is Microsoft.Extensions.AI?
When integrating LLMs into .NET applications, the Microsoft.Extensions.AI library serves as a developer’s best friend. Built on top of Microsoft’s Semantic Kernel SDK, it provides a simple, consistent API to interact with various LLM providers. Here’s why it stands out:
- Unified API for Multiple Providers: Work seamlessly across different providers, such as OpenAI, Azure OpenAI, or local services like Ollama.
- Dependency Injection Integration: Easily integrate AI functionality into .NET projects while following dependency injection best practices.
- Flexibility: Switch between cloud-based and on-premises models without modifying your core application logic.
With these features, Microsoft.Extensions.AI minimizes the complexity of LLM integrations, letting developers focus on adding AI capabilities without diving deep into the configuration specifics.
What is Ollama?
Ollama is a powerful tool that allows developers to run Large Language Models (LLMs) locally on their own machines. By leveraging Docker, Ollama offers an API interface to interact with LLMs like Llama 2 or other popular open-source models. This is especially useful for developers who prioritize privacy, offline functionality, or lower latency, as it removes dependency on cloud-based services.
Popular Models on Ollama
Ollama provides an impressive selection of AI models tailored for different use cases. Here are some notable examples:
- Llama 3: A cutting-edge general-purpose language model with strong reasoning and conversational capabilities.
- MathΣtral: Designed for solving complex mathematical problems and scientific reasoning.
- StableLM-Zephyr: Lightweight and optimized for responsive outputs without high hardware requirements.
- CodeBooga: A high-performance model built specifically for code generation and understanding.
- Reader-LM: Focused on converting HTML content to Markdown, ideal for content workflows.
- Solar Pro: Advanced for larger projects, it fits single GPUs with 22 billion parameters.
- DuckDB-NSQL: Converts natural language into SQL queries for database tasks.
Check out the full list of supported models at Ollama Models to explore your options and find the right model for your use case.
Introducing Ollama: Running LLMs Locally
For developers who want to avoid relying entirely on cloud services, Ollama is a game-changer. Ollama makes running popular LLMs locally incredibly simple by:
- Eliminating latency and privacy concerns associated with cloud services.
- Providing containerized LLMs using Docker.
- Supporting various open-source models like Llama with optimized configurations.
Example: Building a .NET Console Application with Microsoft.Extensions.AI and Ollama
Disclaimer: This example is intended for educational purposes only. While it demonstrates key concepts, there are more efficient ways to write and optimize this code in real-world applications. Consider this a starting point for learning, and always aim to follow best practices and refine your implementation.
Prerequisites
Before starting, make sure you have the following installed:
- .NET SDK: Download and install the .NET SDK if you haven’t already.
- Visual Studio Code (VSCode): Install Visual Studio Code for a lightweight code editor.
- C# Extension for VSCode: Install the C# extension for VSCode to enable C# support.
- Docker: Install Docker.
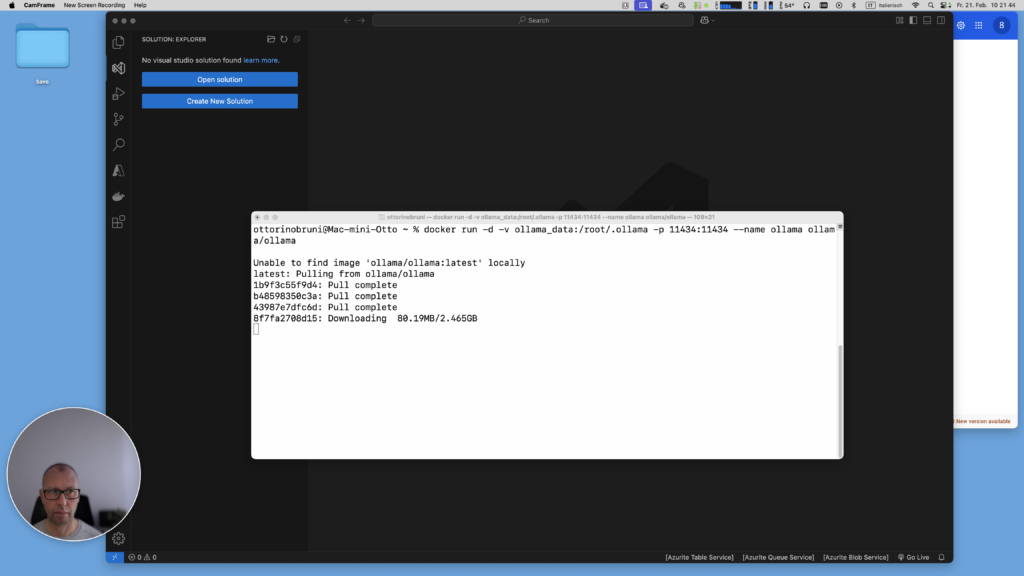
Step 1: Setting up Ollama
Start the Ollama Docker container:
docker run -d -v ollama_data:/root/.ollama -p 11434:11434 --name ollama ollama/ollamaPull the Llama 3 model (or any other supported model):
docker exec -it ollama ollama pull llama3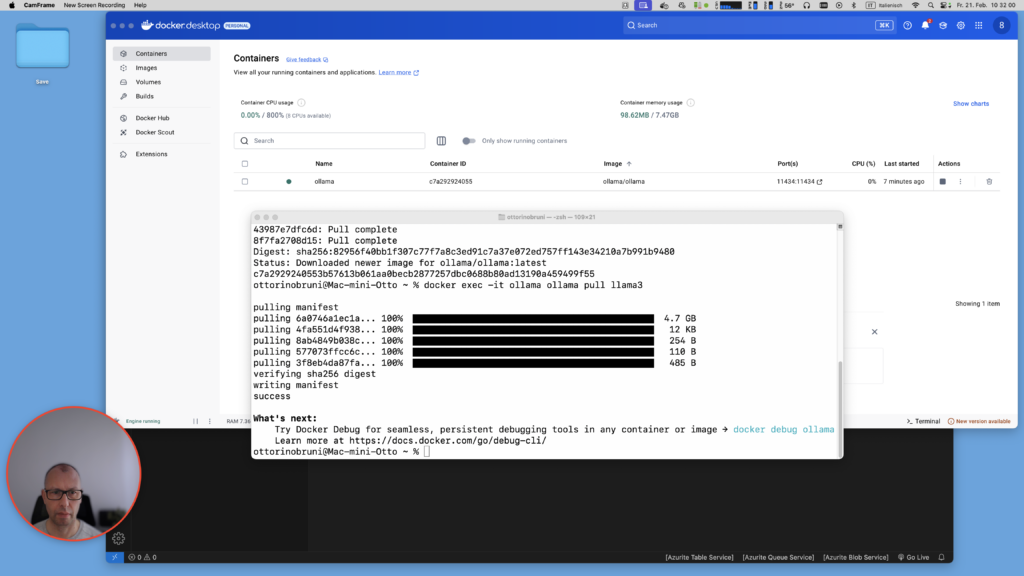
Step 2: Create a new console app
Run the following in your terminal:
dotnet new console -o LlmConsoleApp
cd LlmConsoleAppStep3: Add the required NuGet packages
Install the core libraries for working with Microsoft.Extensions.AI and Ollama:
- Microsoft.Extensions.AI # The base AI library
- Microsoft.Extensions.AI.Ollama # Ollama provider for local LLMs
- Microsoft.Extensions.Hosting # Manages app lifecycle and services
dotnet add package Microsoft.Extensions.AI
dotnet add package Microsoft.Extensions.AI.Ollama
dotnet add package Microsoft.Extensions.Hosting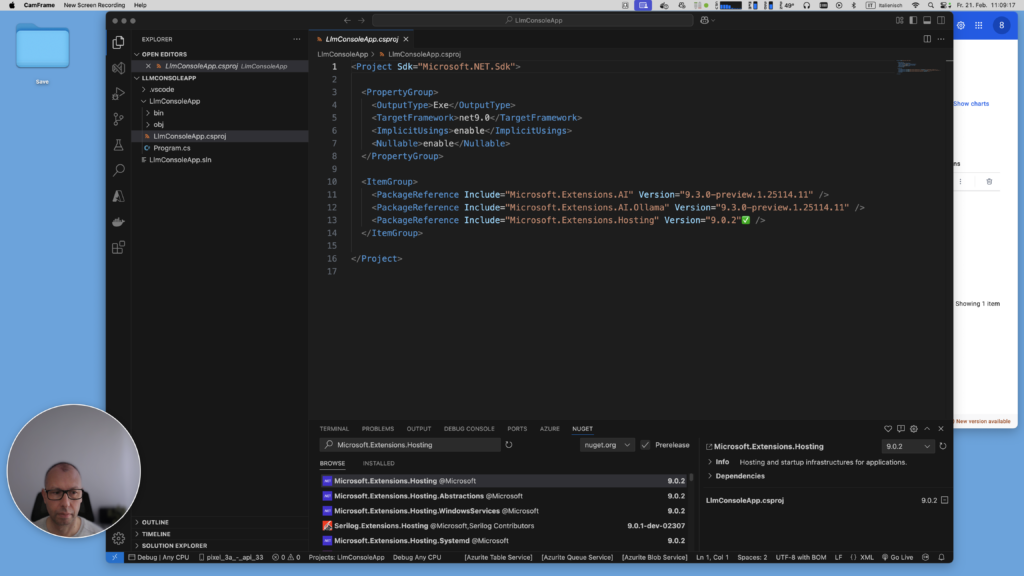
Step 4: Coding the Console App
Here’s the full example code for integrating an LLM into a console app:
// Create a .NET application builder with Dependency Injection
using Microsoft.Extensions.AI;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Hosting;
using Microsoft.Extensions.Logging;
var builder = Host.CreateApplicationBuilder();
// Register AI chat client with the specified LLM model
builder.Services.AddChatClient(new OllamaChatClient(
new Uri("http://localhost:11434"), "llama3") // Replace with your preferred model if needed
);
// Configure logging to output messages to the console
builder.Services.AddLogging(config => {
config.ClearProviders();
config.AddConsole();
});
// Build the application
var app = builder.Build();
// Retrieve the chat client from the service provider
var chatClient = app.Services.GetRequiredService<IChatClient>();
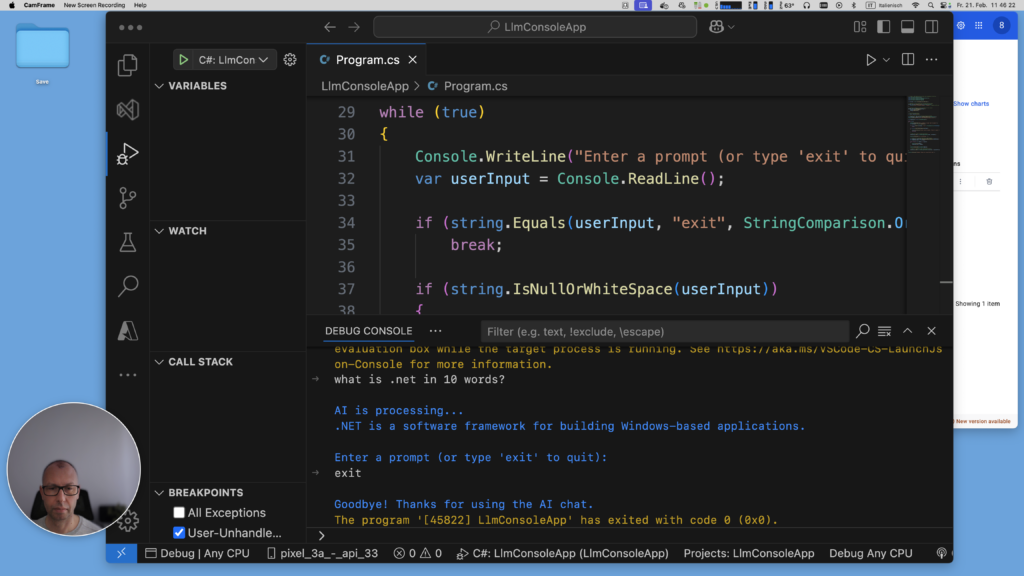
Console.WriteLine("Welcome to the AI-powered Console Chat!");
var chatHistory = new List<ChatMessage>();
while (true)
{
Console.WriteLine("Enter a prompt (or type 'exit' to quit):");
var userInput = Console.ReadLine();
if (string.Equals(userInput, "exit", StringComparison.OrdinalIgnoreCase))
break;
if (string.IsNullOrWhiteSpace(userInput))
{
Console.WriteLine("Prompt cannot be empty. Please try again.");
continue;
}
// Add user's input to the chat history
chatHistory.Add(new ChatMessage(ChatRole.User, userInput));
Console.WriteLine("AI is processing...");
// Stream the AI response and add to chat history
var response = chatClient.GetStreamingResponseAsync(chatHistory);
var responseString = string.Empty;
await foreach (var update in response)
{
Console.Write(update);
responseString += update;
}
Console.WriteLine(Environment.NewLine);
// Add AI's response to the conversation history
chatHistory.Add(new ChatMessage(ChatRole.Assistant, responseString));
}
Console.WriteLine("Goodbye! Thanks for using the AI chat.");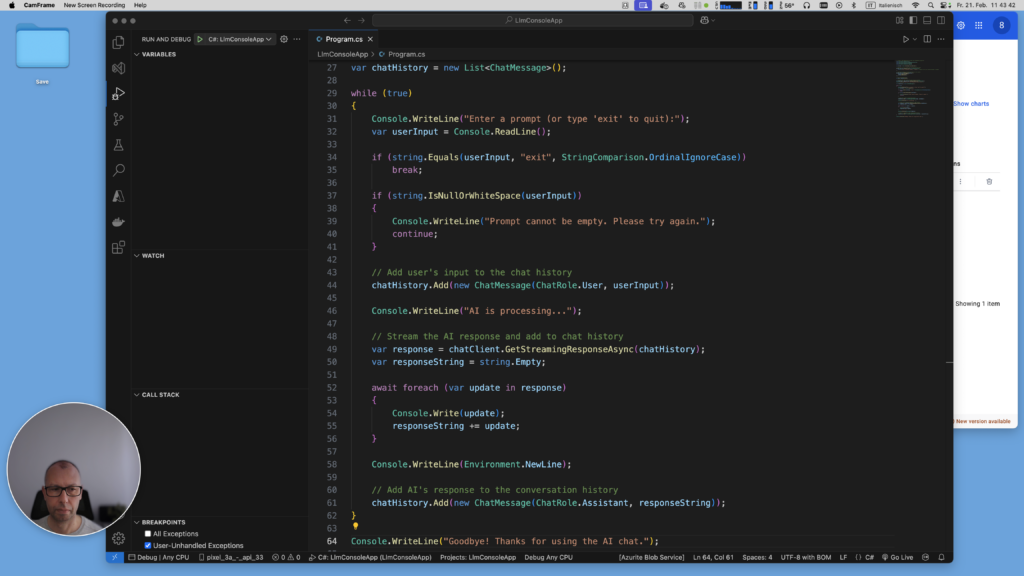
How It Works
Setting Up Dependency Injection:
The app uses .NET’s dependency injection to configure and resolve the IChatClient provided by Microsoft.Extensions.AI. This allows the LLM to be seamlessly integrated into your application.
Interacting with the LLM:
The chatHistory object ensures that context is preserved between prompts, allowing for more natural interactions. Using CompleteStreamingAsync, the AI streams its response piece by piece for real-time feedback.
Step 5: Running the App:
Run the console application with the following command:
dotnet runEnter a prompt (such as “What is .NET?”) and watch as the LLM provides a detailed response. Type exit to quit the app.
Conclusion
In this guide, we’ve taken our first steps into the world of integrating Large Language Models (LLMs) with .NET applications using Microsoft.Extensions.AI and running models like Llama 3 locally via Ollama. While this example covered the basics of getting started with a console application, it’s just a small glimpse of what’s truly possible with these tools.
By experimenting with LLMs and their capabilities, you’ll uncover countless possibilities, from automating workflows to building intelligent, user-facing applications. With the setup we’ve explored today, you now have everything a developer needs to dive deeper into LLMs, try out various models, and bring AI-powered functionalities to life.
As developers, it’s essential to keep testing and exploring new technologies. Staying curious and experimenting will open doors to innovation and help you stay ahead in the ever-evolving tech industry.
If you enjoyed this article, let me know! Next time, I could explore a more advanced example, such as building an intelligent Minimal API or even creating a more interactive app using MAUI.
If you think your friends or network would find this article useful, please consider sharing it with them. Your support is greatly appreciated.
Thanks for reading!
 Discover CodeSwissKnife, your all-in-one, offline toolkit for developers!
Discover CodeSwissKnife, your all-in-one, offline toolkit for developers!
Click to explore CodeSwissKnife 